Upload Csv File to S3 Line by Line + Java
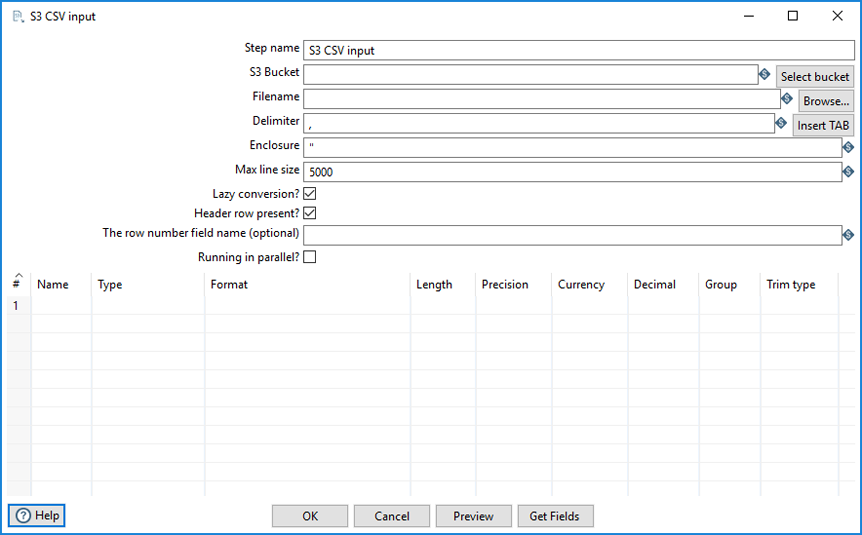
S3 CSV Input

The S3 CSV Input step identifies and loads a CSV file from an Amazon Simple Storage Service (S3) bucket into your transformation.
Options
CircumspectionFor technical reasons, parallel reading of S3 files is only supported on files that do not have fields with line breaks or carriage returns in them.
The following options are available for the S3 CSV Input transformation step.
| Option | Clarification |
| Footstep name | Specify the unique name of the S3 CSV Input step on the canvas. You lot can customize the proper name or get out information technology as the default. |
| S3 Bucket | Specify the S3 container where the CSV object file is stored. Or click Select bucket to browse to and select the S3 container where the CSV object file is stored. |
| Filename | Specify i of the following names (or click Browse) for the input file:
The file name of a file in the S3 Deject uses the following schema: s3n://s3n/(s3_bucket_name)/(absolute_path_to_file) |
| Delimiter | Specify the file delimiter grapheme used in the source file. The default delimiter for the CSV File Input footstep is a semicolon (;). Click Insert Tab to use a tab as the delimiter. Special characters can be set with the format: For example: |
| Enclosure | Specify the enclosure grapheme used in the source file. The default value is double quotes ( Special characters can be fix with the format: For example: |
| Max line size | Specify the maximum characters to be read per line by the input operation. The default is 5000. |
| Lazy conversion? | Select this option to delay the conversion of a row of data until it is absolutely necessary. |
| Header row present? | Select to indicate whether the source file contains a header row with column names. |
| The row number field proper noun | Specify the name of the field that volition contain the row number in the output of this step. |
| Running in parallel | Select to indicate whether you will accept multiple instances of this step running (step copies) and if y'all want each instance to read a divide part of the S3 file(due south). When reading multiple files, the total size of all files is taken into consideration to dissever the workload. In that specific example, brand certain that ALL pace copies receive all files that demand to be read; otherwise, the parallel algorithm will not work correctly. |
Fields
You can specify what fields to read from your S3 file through the fields table.
- Click Get Fields to accept the stride populate the tabular array with fields derived from the source file based on the current specified settings (such as Delimiter or Enclosure). All fields identified by this stride volition exist added to the tabular array.
- Click Preview to view the data coming from the source file.
The tabular array contains the following columns:
| Column | Description |
| Name | Specify the name of the field. |
| Type | Select the field's data type from the dropdown list or enter it manually. |
| Format | Select the format mask (number type) from the dropdown list or enter it manually. Run across Common Formats for data on common valid date and numeric formats yous can use in this stride. |
| Length | Specify the length of the field, according to the following field types:
|
| Precision | Specify the number of floating signal digits for number-type fields. |
| Currency | Specify the symbol used to represent currencies. For case: $ or € |
| Decimal | Specify the symbol used to stand for a decimal point, either a period "." or a comma ",". For example: 5,000.00 or 5.000,00 |
| Group | Specify the method used to separate units of thousands in number of 4 digits or larger, either a menstruum "." Or a comma ",". For example: five,000.00 or 5.000,00 |
| Trim type | Select the trimming method (none, left, right, both) to use to a string, which truncates the field earlier processing. Trimming but works when no field length is specified. |
See Understanding PDI data types and field metadata to maximize the efficiency of your transformation and job results.
AWS credentials
The S3 CSV Input step provides credentials to the Amazon Web Services SDK for Java using a credential provider chain. The default credential provider concatenation looks for AWS credentials in the following locations and in the post-obit guild:
-
Environment variables
The variables AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, and AWS_SESSION_TOKEN. See AWS Environment Variables.
-
AWS credentials file
The credentials file, located in the /.aws directory on Linux, macOS, and Unix operating systems, and in the "%UserProfile%\.aws directory on Windows operating systems. See AWS Configuration and Credential Files
-
CLI configuration file
The config file is located in the same directory as the credentials file. The config file can contain a default profile, named profiles, and CLI-specific configuration parameters for each profile.
-
ECS container credentials
These credentials are provided by the Amazon Rubberband Container Service on container instances set up by the ECS administrator. See AWS Using an IAM Part to Grant Permissions to Applications.
-
Instance profile credentials
These credentials are delivered through the Amazon EC2 metadata service, and can be used on EC2 instances with an assigned instance function.
The S3 CSV Input pace can apply whatsoever of these methods to authenticate AWS credentials. For more data on setting up AWS credentials, run into Working with AWS Credentials.
Source: https://help.hitachivantara.com/Documentation/9.1/Products/S3_CSV_Input
0 Response to "Upload Csv File to S3 Line by Line + Java"
Enregistrer un commentaire